OpenAI is bringing new transcription and voice-generating AI models to its API that the company claims improve upon its previous releases.
For OpenAI, the models fit into its broader “agentic” vision: building automated systems that can independently accomplish tasks on behalf of users. The definition of “agent” might be in dispute, but OpenAI Head of Product Olivier Godement described one interpretation as a chatbot that can speak with a business’s customers.
“We’re going to see more and more agents pop up in the coming months” Godement told TechCrunch during a briefing. “And so the general theme is helping customers and developers leverage agents that are useful, available, and accurate.”
OpenAI claims that its new text-to-speech model, “gpt-4o-mini-tts,” not only delivers more nuanced and realistic-sounding speech but is also more “steerable” than its previous-gen speech-synthesizing models. Developers can instruct gpt-4o-mini-tts on how to say things in natural language — for example, “speak like a mad scientist” or “use a serene voice, like a mindfulness teacher.”
Here’s a “true crime-style,” weathered voice:
And here’s a sample of a female “professional” voice:
Jeff Harris, a member of the product staff at OpenAI, told TechCrunch that the goal is to let developers tailor both the voice “experience” and “context.”
“In different contexts, you don’t just want a flat, monotonous voice,” Harris said. “If you’re in a customer support experience and you want the voice to be apologetic because it’s made a mistake, you can actually have the voice have that emotion in it … Our big belief, here, is that developers and users want to really control not just what is spoken, but how things are spoken.”
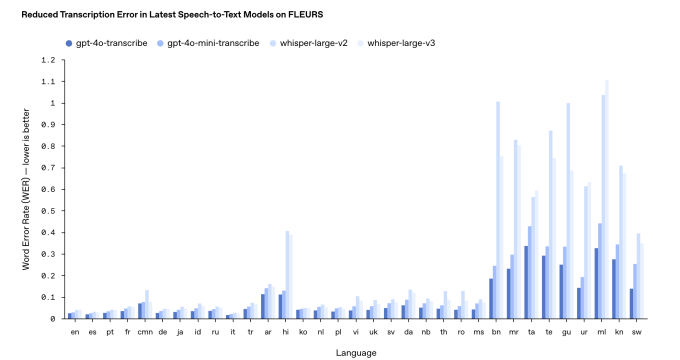
As for OpenAI’s new speech-to-text models, “gpt-4o-transcribe” and “gpt-4o-mini-transcribe,” they effectively replace the company’s long-in-the-tooth Whisper transcription model. Trained on “diverse, high-quality audio datasets,” the new models can better capture accented and varied speech, OpenAI claims, even in chaotic environments.
They’re also less likely to hallucinate, Harris added. Whisper notoriously tended to fabricate words — and even whole passages — in conversations, introducing everything from racial commentary to imagined medical treatments into transcripts.
“[T]hese models are much improved versus Whisper on that front,” Harris said. “Making sure the models are accurate is completely essential to getting a reliable voice experience, and accurate [in this context] means that the models are hearing the words precisely [and] aren’t filling in details that they didn’t hear.”



